Naming things
"The beginning of wisdom is the ability to call things by their right names. " - Confucius.
As a writer, I've always been fascinated with names. How people get their names, what they mean, whether they like them or not. When I was twelve, I bought a baby name book and spent hours poring through the various sections trying to decide on names for characters in short stories I was working on. Is this florist more of a Veronica or a Jane? What signal would it give the reader that the main character has a name that is Germanic origin versus one from Morocco? I was particularly interested in how names traveled between different cultures, where Yonatan, Ivan,João, and John all came from the same root but have entirely different connotations and contexts.
As with most things in literature, there was never a right answer, but there were names that felt right, and names that didn't. Many years later, when I started writing code, I assumed that naming conventions were rigid and that the RectangleBoxBuilderFactory class had existed in perpetuity through eternity.
A fantasy every developer has probably had at some point was, "What if you could entirely rewrite the current codebase you're working on from scratch and pick the names and the logical mappings yourselves."

I recently started to work on Viberary, a semantic search engine that will eventually recommend books based on mood, and so took the opportunity to do just that.
Since it's my personal project, I can shape it however I want. But starting with a blank slate is just as paralyzing as working with a 500K LOC monolith, and I was surprised to find that, just like when I was a preteen writing in my diary, one of my biggest blockers was naming things.
For example, what should you call a class that fetches embeddings generated via sentence-transformers and writes them to redis for nearest-neighbors search? Luckily, I've worked in search, so it was easy for me to call this the Indexer, a short, idiomatic name for a concept that has existed for a long time in search and recommendations, as we can see from the Tapestry paper architecture, one of the first recommender systems, written in 1992.
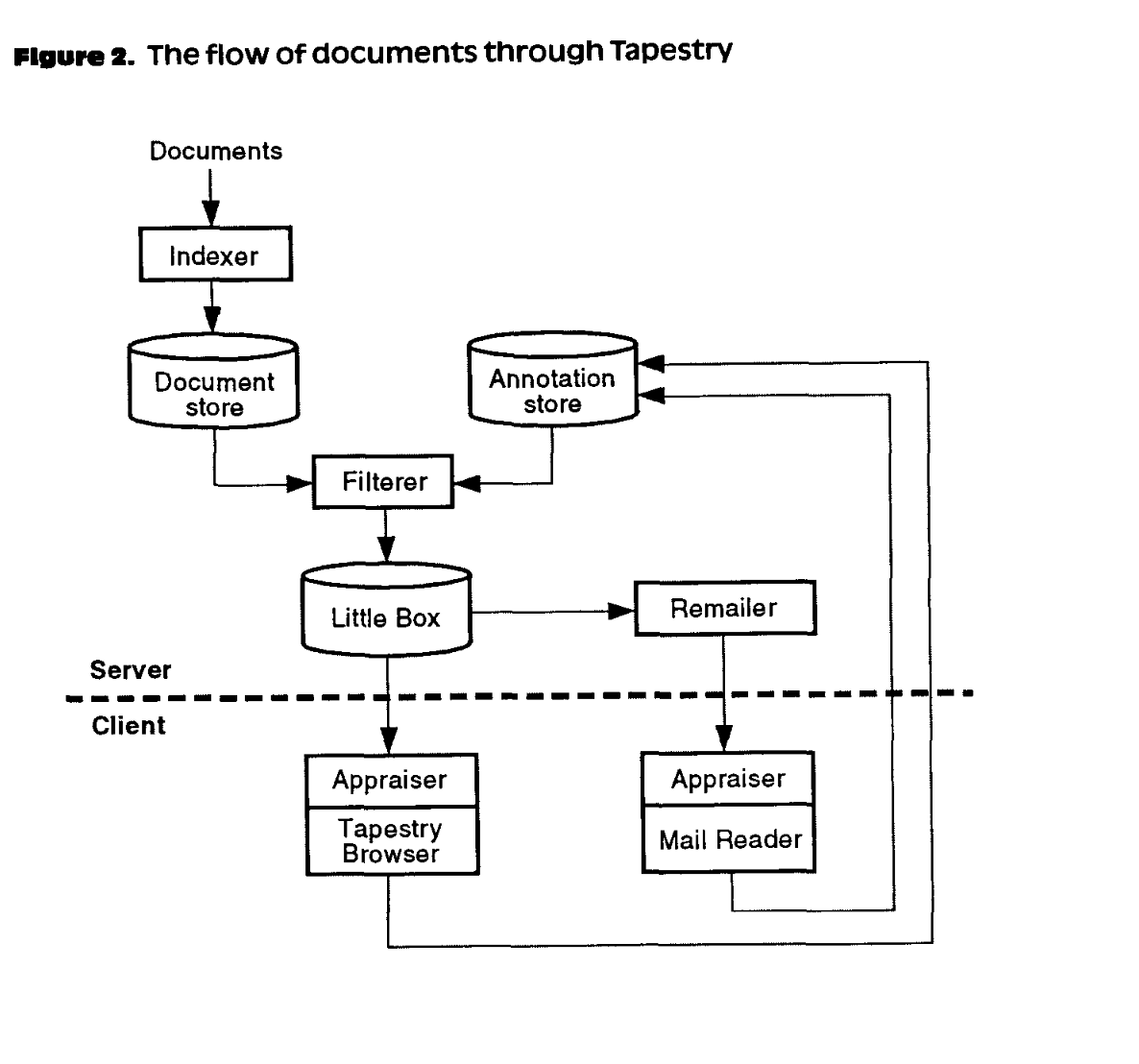
Naming the methods for the class was much harder, and even harder still was picking the name for the file (module itself), because Python allows a file and the classes it contains to have different names, and moreover mandates that,
modules should have short, all-lowercase names. but that classes should normally use the CapWords convention.
There's a reason we often joke that naming things is one of the two hard things in programming, but we often say it in kind of a hopeless, "Haha, this is crazy, what can we do about it" kind of way.
Luckily, I recently came across a gem of a book in my Amazon recommendations, "Naming Things" by Tom Benner, that aims to address this. The book is super short, but I strongly recommend it for anyone looking to get more understanding behind the ghost knowledge that guides naming conventions in programming.
Here are some of my favorite highlights:
- Naming things is hard because not only does the namer need to know exactly what the code does, but the audience for the code changes. We also have different terms for things across the industry and across different lines of business, and there's not enough cross-pollination, so we end up reinventing the same terms over and over again.
- A name will be used again and again in a codebase, and the more we use it, the harder it is to refactor and rip it out, so it's important to pick a good name right from the beginning.
- We should keep in mind several heuristics when picking names: how easy they are to understand, conciseness (aka a name should not have multiple meanings or include redundant words), names need to be consistent throughout the codebase, and we should be able to distinguish it from other names.
There are a lot of very specific examples throughout the book, for example booleans should include is_x or is_not_x in their name, and good methods should avoid implementation details such as process_in_parallel when process is enough.
Otherwise, naming is a hard tradeoff between picking something short and something that's understandable, while keeping in mind that code is meant mostly for other people to read and that's where the struggle of programming lies.
The other interesting thing about this book is its references section. There are a couple of super interesting studies cited, including "How developers choose names", and this ethnographic study of how developers choose names. Its findings, that experienced developers rely on names of methods rather than comments to navigate a codebase, seem fairly obvious, but it's super interesting to see this proved out through observation and experimentation since most programming and reasoning about programming happens when we are alone.
The best resource from the references is the classic Practice of Programming, by Kernighan and Pike, who worked on Unix., a book that I'm so far only two chapters into but have already gotten a lot out of. The first chapter of the book also covers naming, but I also recommend reading this one cover to cover. What's really interesting is the programming problem they go through in chapter 3,
After reading the book, I was keen to put some of the guidelines into practice for Viberary, but it was much, much harder than I anticipated, so I went to ChatGPT to see if it could help me here. Based on my previous experiments.
This seemed exactly like the kind of thing it could help with, and it didn't do a bad job helping me pick a name for my training data modules.
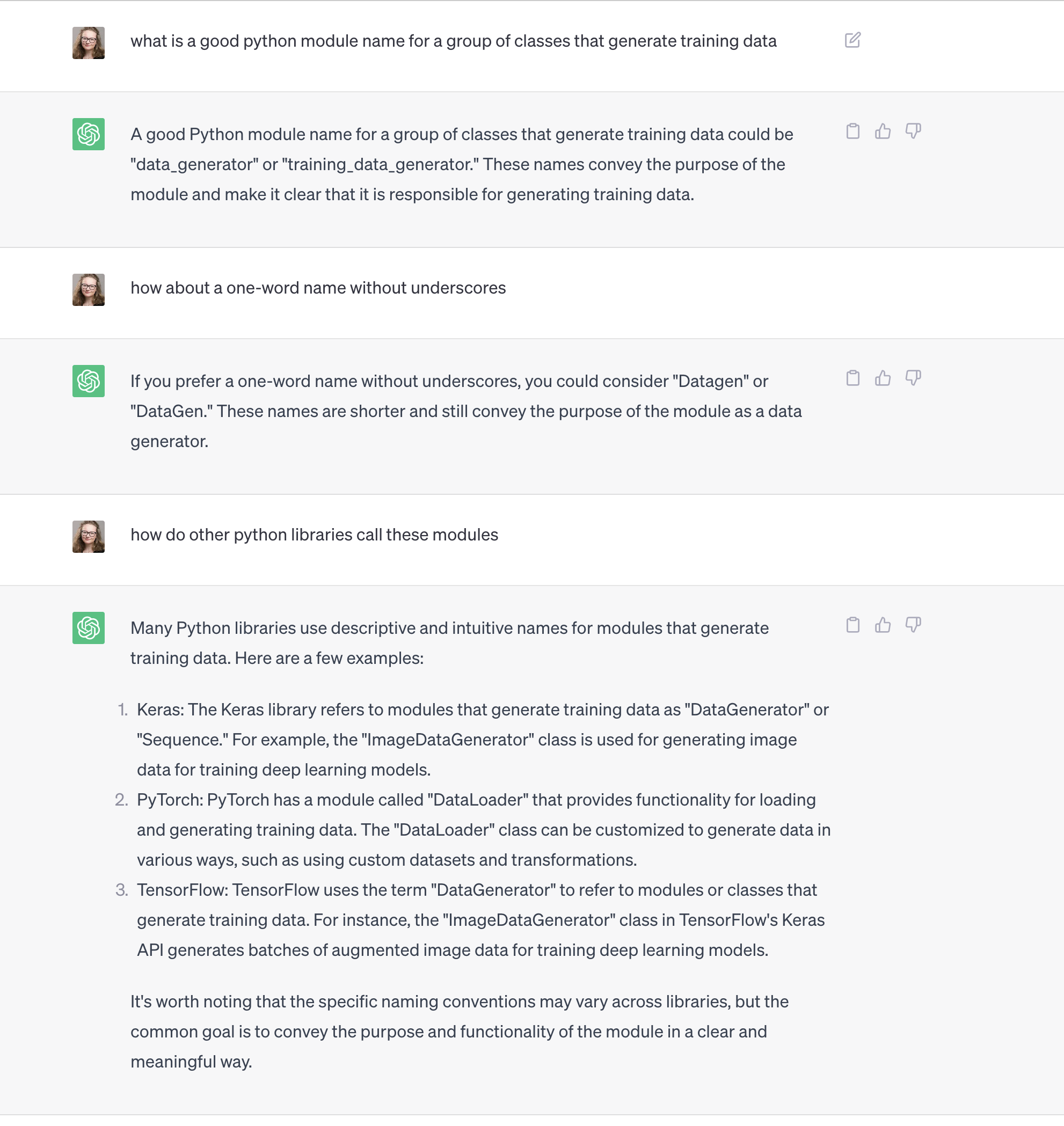
What was most interesting to me in this exchange was not the answer, but the process I went through to get to it. I first had to understand the problem space I was dealing with "a group of classes that generate training data" - that it would be a group versus a single module and that I needed a name to encompass all of them.
I then had to refactor the name to be clearer and shorter so that I wasn't calling data_generator every single time all over my codebase, and, finally, I wanted to see how other developers had dealt with the problem before so that other people reading my code, presumably also Python developers who had used other machine learning libraries, would know where to go.
While I was relying on ChatGPT for idea generation, what struck me about this process was that it was also very strongly based on my own personal judgment and experience as a developer. I was synthesizing not only the naming book, but the years and years I've spent reading different codebases at different companies, open source libraries I've looked at, and talks I've seen.
In a recent fun video on why he doesn't use ChatGPT, a Go developer said something that really struck with me -
When we program by ourselves, we are building patterns. By the time we've been programming five, ten, fifteen years, our minds are full of patterns we can apply to different problems. Picking good names it turns out, is mostly the process of constantly observing the world and providing good abstractions. and the people who are best at this have seen thousands of cases that they can generalize. This is not unlike what the neural network underlying ChatGPT does, but when I think about what I'd like to train more and get better at naming things, it's me rather than the machine.