What we talk about when we talk about The Algo

Quick programming notes: I wrapped up my previous gig a few weeks ago and I’m psyched to be starting as Sr. Machine Learning Engineer at Duo. As always, Normcore updates continue to remain sporadic and highly dependent on my ability to complete an entire eight-hour sleep cycle.
And, another very exciting announcement: NormConf is happening online in December! What started out as a joke tweet has now become a legitimate conference on normcore topics in data and machine learning. Save the date and if you’re interested in sponsoring, shoot me an email!
This March, or maybe it was five lifetimes ago, as part of his on-again-off-again bid to burn the internet to the ground, Elon Musk did a poll to see if the “Twitter algorithm” should be open source.
This, like any of Musk’s bizarre and impulsive tweets launched in between lawsuits, meeting the Pope, and being “house fluid at the moment”, unleashed a wide variety of opinions from everyone, including Jack, the former CEO of Twitter, who responded that people should have a choice of which algorithm to use. But leaving aside the semantics of what “open sourcing” and algoritmic choice, the larger question remained: what actually was The Algorithm?
The OG Algorithm
On Twitter, I was curious as to what the common conception of algorithms was, so I asked and got a range of different, interesting answers that generally aggregated to “an algorithm is a set of instructions, like a recipe, for a program.”
Algorithms seem to be very new because we think of them as inherently related to computers. But, the concept has been with us as long as humans have needed to narrowly navigate extremely complex multi-dimensional space that can have an infinite multitude of outcomes. In other words, humans have been creating algorithms for how to live for thousands of years.
Here is an algorithm on figuring out how our time on earth should be allocated and why:
To every thing there is a season, and a time to every purpose under the heaven:
A time to be born, and a time to die; a time to plant, a time to reap that which is planted;
Here is an algorithm from the witches in Macbeth about how to prepare effective hallucinogenic potables:
Double, double toil and trouble;
Fire burn and caldron bubble.
Filet of a fenny snake,
In the caldron boil and bake;
Eye of newt and toe of frog,
Wool of bat and tongue of dog,Adder's fork and blind-worm's sting,
Lizard's leg and howlet's wing,For a charm of powerful trouble,
Like a hell-broth boil and bubble.Double, double toil and trouble;
Fire burn and caldron bubble.Cool it with a baboon's blood,
Then the charm is firm and good.
And here is a very long, elegant algorithm for how to build human-centric buildings and cities.
We weave an extremely tangled web
When we talk about “The Algorithm” today, though, it’s any program that shapes and influences the sea of content across the different places we traverse online. This Algorithm seems to be entirely out of our control and impossible to penetrate.
In order to start understanding it ,there are a couple of important things to keep in mind. What we as practitioners implicitly mean when we say “The Algorithm” is not one single algorithm, but rather:
Code logic that includes:
Machine Learning Algorithms
Simple if/then statements / hardcoded heuristics
Blended together
Business logic that is either implicitly or explicitly stated:
The results of meetings
Results of memos, discussions, and RFCs
External drivers like changes in the market, support tickets, etc.
All of this results in a system that’s made up of two parts that both equally influence the algorithm: One that is machine-generated, and one that is people (business logic). So, the system is never any one single thing, but a living organism made up of many, many moving complex parts. Every single ecommerce or content-based feed we consume online is a world unto itself that requires an enormous amount of technical and business context to untangle.
For example, here is how you might hypothetically build the algorithm that populates a “Home” feed on Flutter, the premier social network for where things with wings gather.
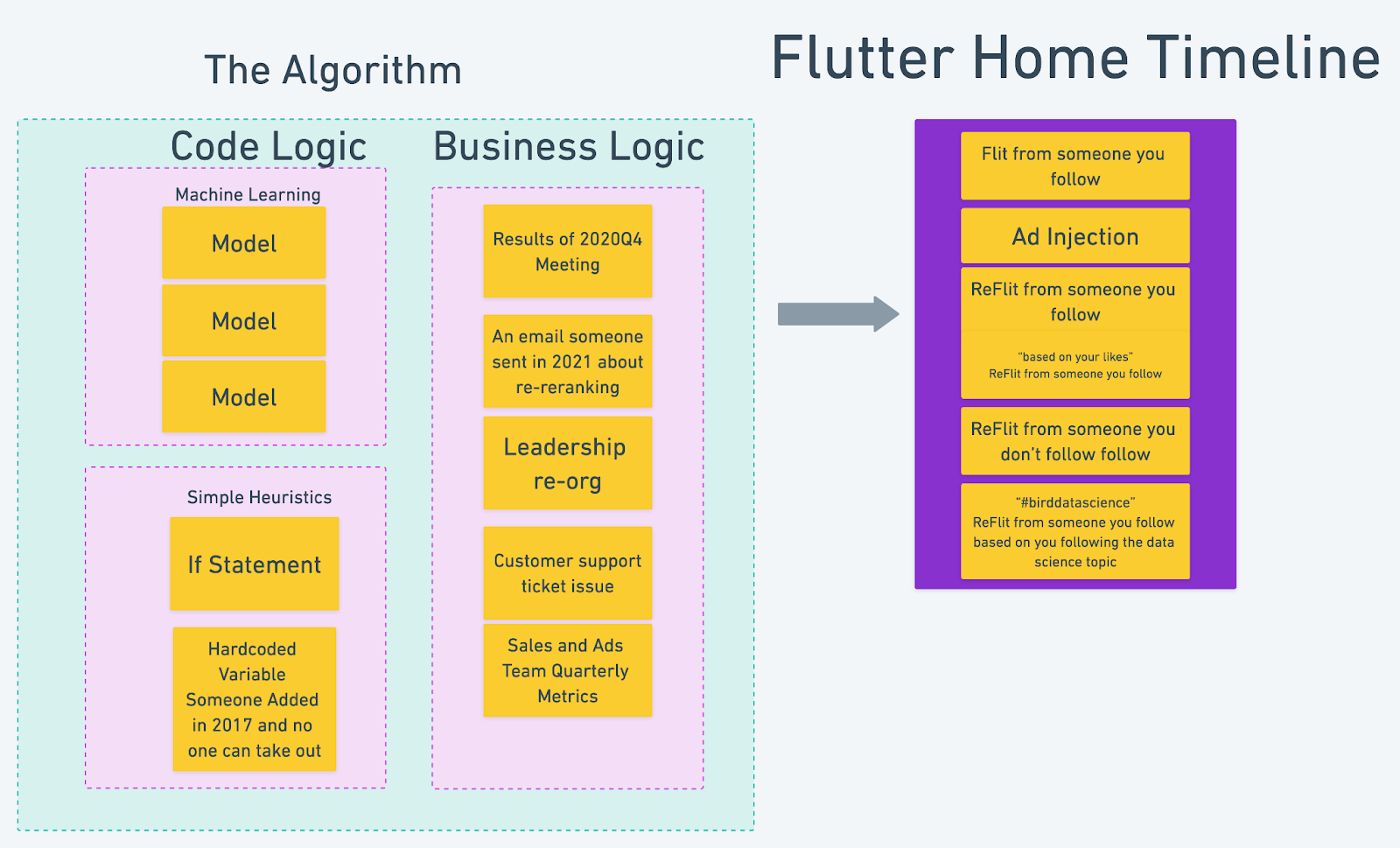
But, let’s start at the beginning.
The Algorithm’s Heart: Code Logic
An algorithm is born when a computer scientist and a product manager love each other very much, have a product vision, and decide that they want to drive either click through rate or revenue.
The PM, the computer scientist, and a team of engineers (called something catchy like BirdFeed) goes off to create a feed. The BirdFeed team sees that, on the initial Flutter home timeline, birds are shown purely content from accounts that they follow.
But, maybe this is not in line with engagement metrics they need for their business. As a result, BirdFeed introduces an algorithmic timeline. (By the way, every timeline is algorithmic - reverse-chronological is also an algorithmic design choice.)
As this very, very excellent post on Twitter’s timeline outlines,
This explanation makes sense from a UX standpoint, and an algorithmic feed certainly gives Twitter a lot more freedom to experiment with the product.
The real motivation, however, is because using an algorithmic feed is incentivized by Twitter’s current ad-driven business model. More relevant content in your feed ⇒ higher engagement ⇒ more ad revenue. This is a classic social network strategy that’s proven to work.
At this stage, we face a fundamental question: how do you shuffle the existing timeline so that it includes content people are more likely to find interesting and engage with?
Generally, there are several ways to tackle this problem, and they involve looking at either a user’s past activity and comparing it to the activity of similar users (collaborative filtering), or looking at a user’s past activity and comparing the items the user interacted with to similar items in the catalog (content-based filtering).
Once you collect a user’s log history and build a model that generates a potential catalog of candidate Flits to recommend to them based on past user activity. But let’s say you come up with 10000 Flits to recommend? You can’t show them all in any given timeline, so what do you do?
You rank your candidate Flits, then filter them against a set of business logic, then rank again until you get to a point where you have only a handful of Flits that you’re likely to insert into the timeline.

This step is the heart of the algorithm and it often involves building multi-step machine learning models that will ultimately generate a small set of candidates. Each company has a system that has developed using a variation of these steps and they all look strikingly similar.
Intermingled with the machine learning code are decisions that come from business logic: is there a list of bad words in Flits that we need to filter out of all potential recommendations? Maybe we don’t want to show Flits from Hummingbirds at all? Maybe we only want 9 Flits, not 10, for some arcane business reason like maybe the CEO likes the number 9. These are all hardcoded in the ML flow.
These machine learning systems then grow so involved that there are meta-systems being developed to manage them. Here is a diagram of what’s involved in MLOps, the field around operationalizing these algorithms. I see this diagram in my nightmares sometimes.


The Algorithm’s Soul: Business Logic
The model itself is usually what we think about when we think about the algorithm. But, the second part of the system is just as complex and includes a number of participants: product managers, project managers, advertising teams, content safety teams, and many, many more, in a back and forth about what The Feed should look like.
Because, then the question becomes, now that we have some candidate Flits, how do we insert those Flits amongst the chronological Flits that birds are already receiving? Should your feed be entirely chronological? 50% chronological and 50% algorithmic? Mostly algorithmic? What if you have more than one algorithm, one that shows you the most relevant Flits that other birds have liked, and one that shows the top flits from trending Bird Topics on Flutter? How do you combine those two sources? What if you have too many Flits in n seconds from the same Bird? How do you blend in diversity with Flits from Butterflies and Mosquitoes? What if you have Bad Bird Actors that are constantly either spamming or sending lewd pictures of their cloacas to the Timeline? How do you downrank them? Should you?
And now, finally, you get to the question of injecting ads, the entire reason Flutter continues to work. How often can you insert them without user fatigue while still maximizing revenue? What content can they be next to? Can you have an ad for worms shown to a Flutter user who is profiled as a Butterfly, and therefore does not eat worms? How should you promote ads across timelines? This in itself is an entire world.
These gray-area business logic questions where recommender systems become just as much of an art as a science, continuing to generate potential content for recommendation, blending it, filtering out negative or prohibited content on the platform to get to a “good” feed of engageable content.
They involve not only the code itself, but also hundreds of hours of conversation, back-and-forth, the results of A/B tests for millions of users in re-ranking the feed, changing it, constantly shaping it to the best version of what the company thinks it should be.
Aside from all these decision-making conversations, you have hundreds of organizational changes happening that quietly shape the feed, but that are never documented anywhere. Maybe the engineering team logging user data is accidentally not logging Bird Geolocation anymore. Now your model is inaccurate, but you don’t know about it yet. Maybe the mobile team is running an A/B test that directly conflicts with your feed changes. Maybe you had a reorg and the last CMO loved The Algorithm but the new one doesn’t. And vice versa. All of these changes implicitly silently change the feed on a day-by-day, minute-by-minute basis, but are not anywhere in the model’s documented code.
When the Black Box Opens
The scenario I’ve described is hypothetical, only in the sense that there is sadly not (yet) a social network just for birds and insects. But these kinds of systems get built and decisions get made every day at companies all across the board. Here’s a recent one from Pinterest, for example, and here is Netflix, the king of recommender system’s whole website on their methodologies. Here is Facebook on their re-algorithmized main feed.
But, to the end user, there are several fundamental problems. First, you shouldn’t need to be able to reverse-engineer academic papers to understand your content feed. And second, with so much implicit business logic injected into the system, how can anyone possibly hold the whole feed’s context in their head? How do you know why a single Flit was shown to you? How about a timeline? Many people in the company, even sometimes the engineers that build the systems, don’t.
So even if Twitter were to open-source the algorithm, and you had a background in computer science, all you’d have to look at would be a bunch of code that looks much like the psuedocode generated here, with a number of other, related systems feeding into this timeline code.
You would have zero context about both the code and the business logic used to generate, and, most importantly, you wouldn’t have access to the heart of what makes this system tick: user log data and the logic for how it’s stored, cleaned, and processed in order to be used in both the recommendation algorithms and the construction of the feed itself.
Opening the code of the algorithm might be a good place to start, but it’s not unlike making an architectural excavation site open to the public: without the guidance of an archaeologist to explain it, it’s just a set of pottery shards.
There is not much we as end users can do with “The Algorithm” as-is.
Where do we algo from here?
The good news is that as more people are expressing intense interest in looking at these internals, more companies are also thinking about how to talk about The Algorithm in public.
First, product management teams are trying to make their algorithms transparent. Or, as transparent as they can without exposing proprietary internal business logic. The first time I saw this happen was when Instagram wrote a primer about its recommendation systems aimed at the general public in 2021. They wrote,
It's hard to trust what you don't understand. We want to do a better job of explaining how Instagram works. There are a lot of misconceptions out there, and we recognize that we can do more to help people understand what we do.
Of course, it’s extremely high-level and addresses only some of the elements I touched on in this post, but it’s truly the first time I’ve seen the nature of recommendations explained to a non-technical audience.
Instagram had a second go at this when they made an enormous change in their algorithm a few weeks ago to prioritize video content so they, like every single social platform on the planet right now, could compete with TikTok. People were pretty angry at the new feed, and Adam Mosseri took to Twitter to try and explain it:

(Instagram almost immediately rolled back the changes he discussed. )
Twitter also has recently explained some changes it makes in its recommendation algorithms, For instance, recently, it became overrun with recommendations of tweets from an account called “Shirts that Go Hard”, and, in response, Twitter paused several A/B tests and personalization changes:

These explanations don’t and can’t give all the product context: much of it is proprietary. Some of it will make the company look bad. And some of it, not everyone ven knows. But it’s a start.
Aside from product management-driven explanations, something that’s becoming more prevalent in technical implementations of these systems is more annotated surface areas for recommendation systems. What this means is that the algorithm, as it’s presented in the feed, is labeled or annotated with some level of explanation. The most interesting place I’ve seen it is Meta’s new BlenderBot (experimental chatbots where the entire internet can enter freeform text always being a great idea).
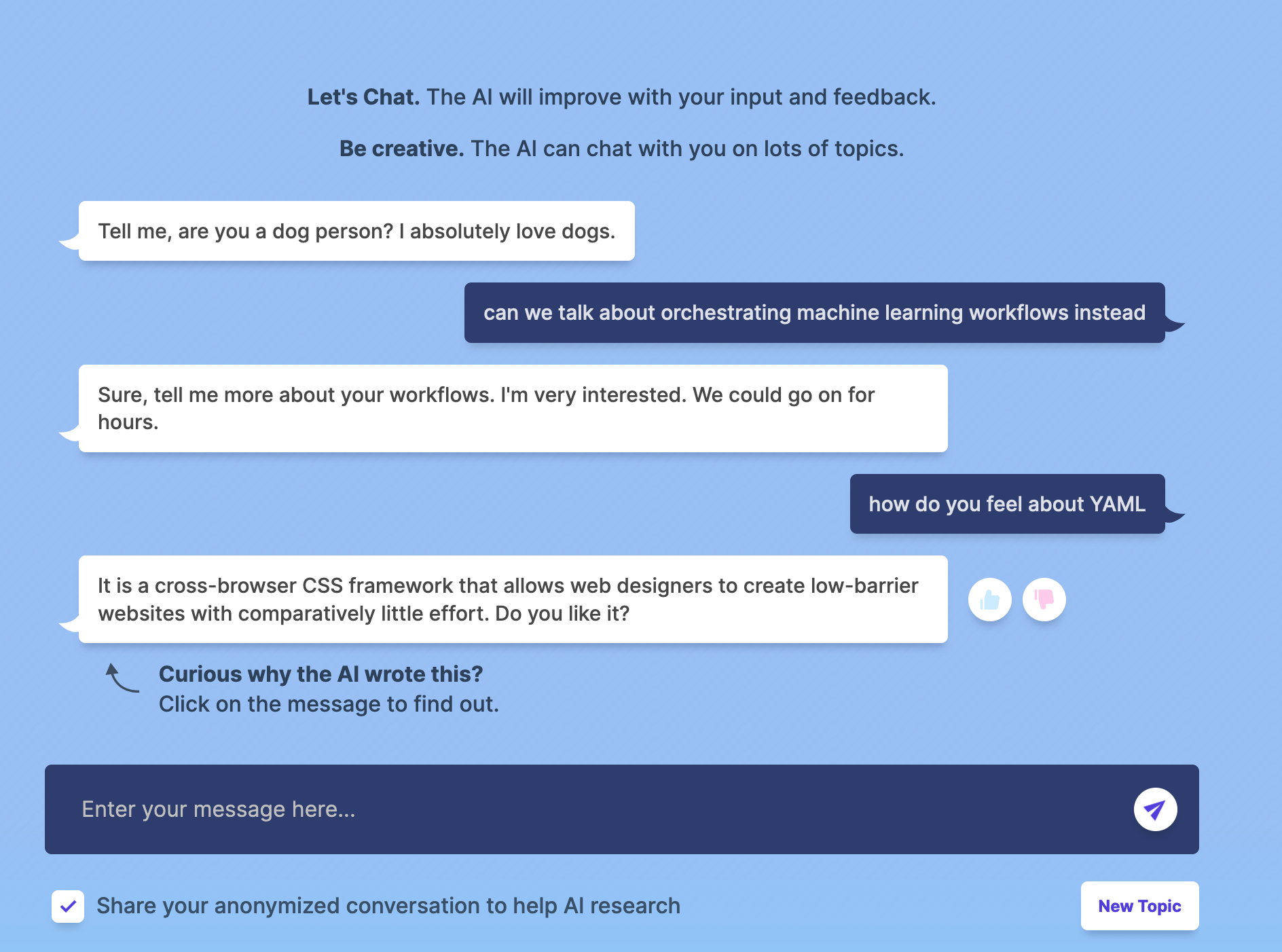
When you enter text, it allows you to mark the immediate response as positive or negative, presumably as user feedback into the model that’s explicit (rather than the implicit, log-based feedback that is usually generated.)
It then also has a short explainer on why the AI responded with the message it did, which pulls up a dialog box around user input. In my case, the AI was 100% wrong about the context of the response, but at least now I (kind of) know why. I can also even go back to the model and try to reverse-engineer exactly what happened.
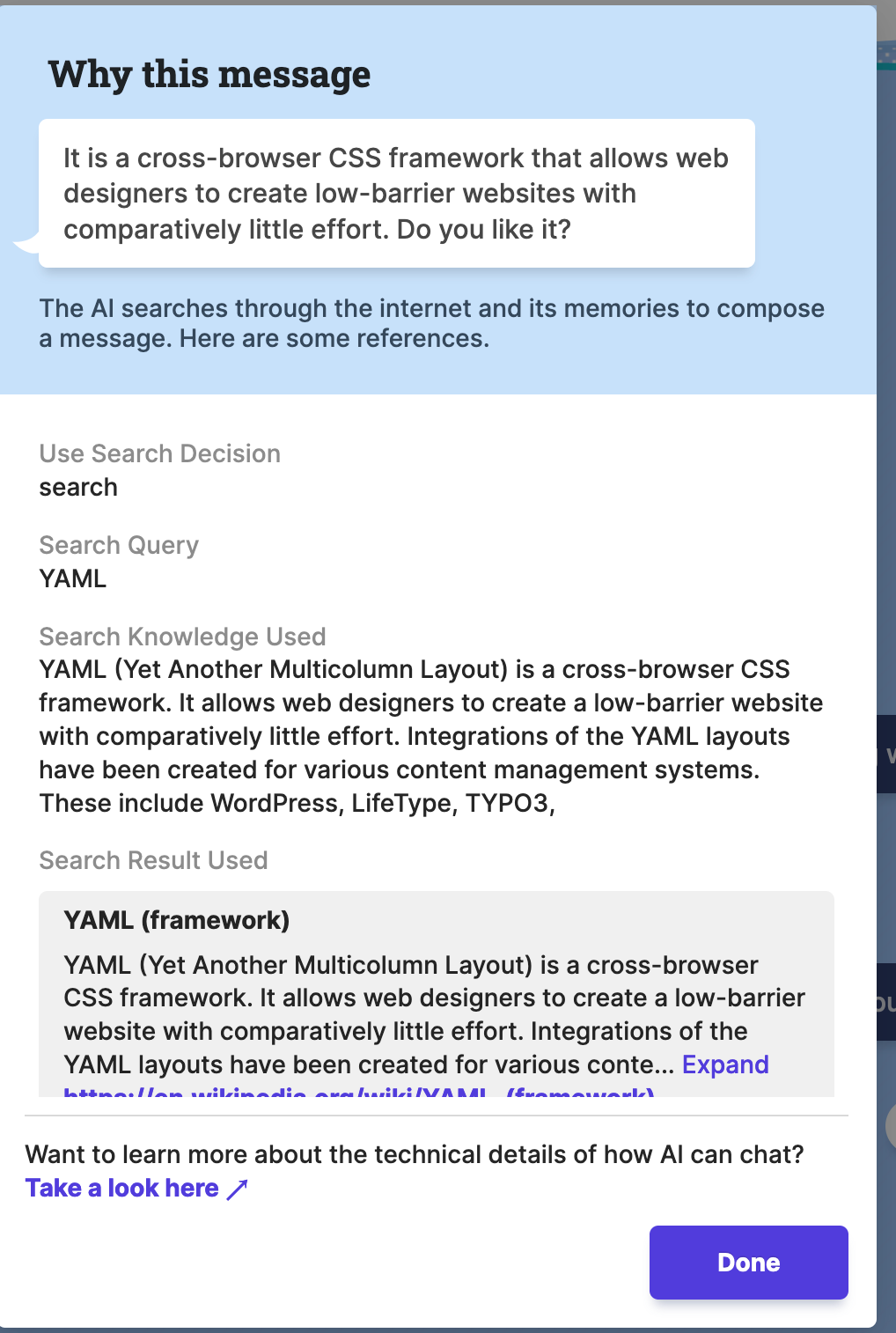
This kind of UI takes an enormous amount of work to implement and loop back into the model’s back-end as a feedback loop, and also adds load time to any given site, so I appreciate the effort and also appreciate that for now it will likely remain mostly a prototype. But , it remains a good example of what an annotated system like this could potentially look like.
We are still in the steam-powered days of machine learning and all of these things, the top-down executive explanations and the engineering efforts at transparency, show just how hard it is to A) Define an algorithm. B) Capture its surface area C) Understand its scope and impact and D) Try to change it.
It doesn’t mean we shouldn’t try. But it does mean we should be more deliberate than just trying to “Open Source The Algorithm.”
Building and hardening these systems was our work for the last 15 years. Continuing to build them so they don’t break AND figuring out how to open them and explain them will be the next 15.