You don't need Kafka

A couple days ago, I was perusing the excellent Data Engineering Weekly newsletter (which I highly recommend subscribing to if you’re in the industry), when I noticed a link to a meetup on Kafka, hosted by WeWork.


For those fortunate enough to never have worked with big data, Kafka is a very complex piece of distributed software that coordinates data transfer between multiple computers. More specifically, what it does is “flattens” data so that it can move it quickly from one place to the other. Where you usually need Kafka is if you have a LOT of data that you need to process very quickly and send somewhere else. Kafka can also store as a retention mechanism, keeping data for 2,3, or even 7 days - that way if your downstream processes fail, you can reprocess using what’s in Kafka.
A lot of companies that deal with data that comes in aggregate (i.e. social network data like Facebook and Twitter, astronomers who process enormous amounts of star movements per night, or autonomous car companies that need cars to quickly understand data about their environments) have set up Kafka as a way to move data from wherever they’re producing data (i.e. with user input at the keyboard, from telescope readings, from car telemetry), to places further downstream that can process and analyze it. The flow usually looks something like this:
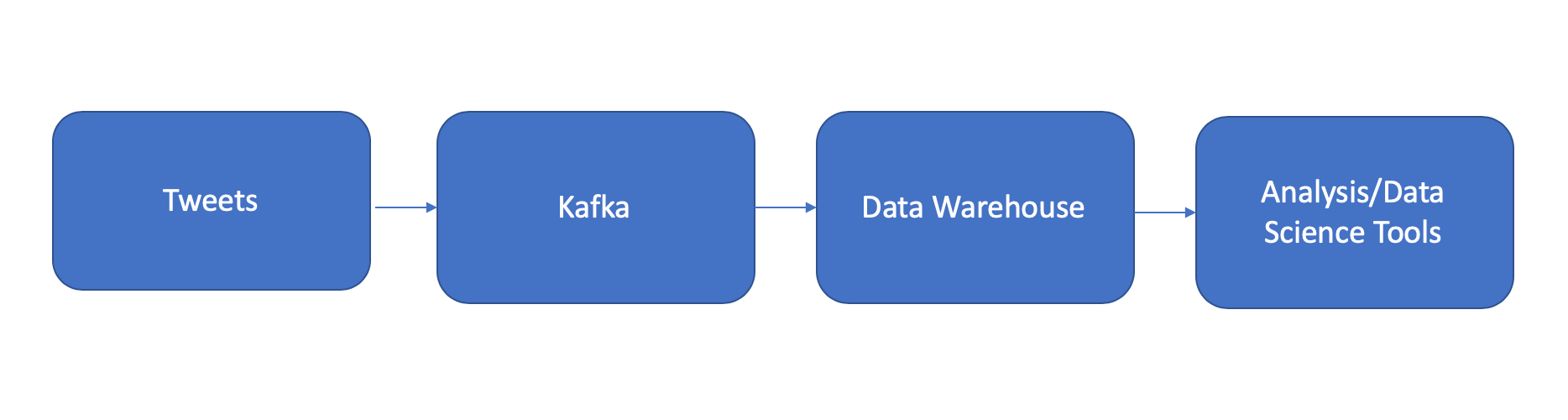
WeWork, now rebranded as The We Company, is the latest success in the coworking space, who claims on their website that their mission is to
“elevate the world’s consciousness.” Its core business is leasing office real estate and then subleasing that office space to individuals and small companies who can’t commit to a traditional office lease.
It’s elevated the world’s consciousness” by creating bespoke places where both individuals and companies can work as teams in offices that look unique, yet vaguely the same (sidenote: I highly recommend you read this article about how all AirBnBs and coffee shops look the same), all around the world. It’s also lately been dabbling in education and, checks notes banning meat.
WeWork recently IPOed (went public), and some of its financial information came to light:
WeWork doubled its revenue from $886 million in 2017 to roughly $1.8 billion in 2018, with net losses hitting a staggering $1.9 billion. These aren’t attractive metrics for a pre-IPO business; then again, Uber’s currently completing a closely watched IPO roadshow despite shrinking growth. Here’s more from Crunchbase News on WeWork’s top line financials:
WeWork’s 2017 revenue: $886 million
WeWork’s 2017 net loss: $933 million
WeWorks 2018 revenue: $1.82 billion (+105.4 percent)
WeWork’s 2018 net loss: $1.9 billion (+103.6 percent)
On the bright side, per Axios, WeWork established a 90 percent occupancy rate in 2018, with total membership rising.
WeWork is often referenced as the perfect example of Silicon Valley’s tendency to inflate valuations. WeWork, a real estate business, burns through cash rapidly and will undoubtedly have to work hard to convince public markets investors of its longevity, as well as its status as a tech company.
What can a message broker technology do for a company that has emphatically said it’s not a real estate company (and is bleeding money left and right)? In the Meetup announcement, WeWork mentions that it uses Kafka for its “on-premise IoT needs.” What could this mean?
“Physical space is our product,” said WeWork chief development officer David Fano, who donned a T-shirt emblazoned with the words “bldgs = data” for the roundtable.
A compact, wall-mounted green box is one of 10 environmental sensors tracking the interior temperature, humidity, air quality, barometric pressure, and ambient light levels. White, wall-mounted beacons, 20 in all, distributed across common spaces (open desk areas and meeting rooms) triangulate the indoor position of WeWork members (the data is anonymized). And an overhead sensor, one of four, uses computer vision to observe member occupancy.
In other words, WeWork is tracking multiple physical events at WeWork and recording all of that data. But…do they really need to do so? How does knowing the ambient temperature of an open area with a Keith Harring mural give them a competitive advantage? And, more importantly, are they using that information for the important things?

Since WeWork is primarily funded by subscriptions, particularly from businesses, it makes sense to optimize the space for these customers:
And it is important for the company to know how well a location’s “unit mix”—what it calls the ratio of private offices, meeting spaces, and open desks—works so it can tweak the formula at the next location.
Something I want to establish for this newsletter are the mental models that I use when thinking about technology. Ben Thompson does this really well for Stratechery where he maps out aggregation theory, and I’m still working on setting up a website for these, but if I had to pick the first one, it would be:
Most startups (and big companies) don’t need the tech stack they have.
At the risk of being one of those armchair Hacker News developers who thinks they can build Facebook alone over the course of a weekend, let me speculate a little over WeWork’s actual business and architecture problems:
What the hell is the point of tracking “barometric pressure” when all WeWork needs is to count the number of people coming in and out and to do optimization work on that capacity planning? If you have an ID with WeWork, you’re either tied to an individual or a company. It would be much easier to install a check-in system tied to badges in the lobby and require badging in to conference systems.
The first one doesn’t require Kafka at all:
WeWork has (currently) 280 locations. Let’s assume that each location sees on average 1,000 members per day, which is probably high for some. That’s 280,000 transactions/day. Let’s assume that each person comes in once for breakfast, clocks out and in at lunch, and leaves. That’s four transactions per person. That’s 1 million events per day, a value that’s easy to store in Postgres, a common open-source relational database. Postgres can do, conservatively, 10,000 writes per second - a lot more if you tune it correctly. For 1 million events per day, that’s 11 writes per second. Not even an issue.
The second one is potentially getting to larger levels of data with the amount of people booking meeting rooms, but you don’t need to stream that data. You can batch it or collect it at the end of the day, again using boring relational technologies.
The overhead in setting up Kafka versus a very hefty Postgres (or BigQuery, or your relational database of choice instance hooked up to a web service receiving JSON sensor data) is enormous, because distributed systems are hard - really hard - and much, much harder than traditional systems.
Kafka is a very good, strong tool when it’s actually needed and one that most companies should think twice about using first. It’s the equivalent of using a hammer to kill a fly - or, in this case, tracking the fly’s barometric pressure through bespoke open areas.
While many use cases don’t require Kafka, it’s an easy tool for developers to recommend it so they can both work on it and talk about it later. It’s not always obvious to even developers themselves - sometimes they like working on shiny things out of the best intentions.
Overarchitecture is real. As Nemil says in this fantastic post,
Early in your career, a surprising number of poorly engineered software systems are due to mistakes with engineering media.
In college and at bootcamps, your primary exposure to engineering is through engineering media like Hacker News, meetups, conferences, Free Code Camp, and Hacker Noon. Technology that is widely discussed there — say micro services or a frontend framework or the blockchain — then unnecessarily shows up in your technology stack.
Using these tech stacks leads companies to take on unnecessary debt, which leads them to have to seek out even more money in the VC cycles instead of running lean and weaning themselves off other peoples’ money.
It’s a trend that unfortunately will only continue, and one that maybe only going public, like We did, will expose.
(By the way, I would love to hear from people who work for companies like this, whether they think their tech stacks are justified or not - especially if you work at WeWork - so hit me up!)
Art: Der Schulspaziergang, Albert Anker, 1872
What I’m reading lately
If you haven’t read the Facebook moderator article yet, I highly encourage you to do so
Why are people avoiding the news? Not because it’s fake, but because there’s too much of it.
Pictures of Hong Kong students studying while protesting
“What are the signs you have a great manager?”
About the Author and Newsletter
I’m a data scientist in Philadelphia. This newsletter is about tech and everything around tech. Most of my free time is spent kid-wrangling, reading, and writing bad tweets. I also have longer opinions on things. Find out more here or follow me on Twitter.
If you like this newsletter, forward it to friends!